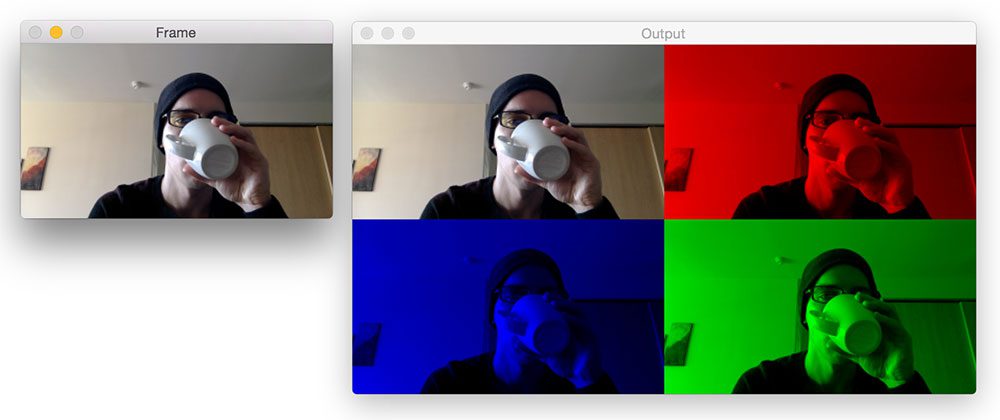
![]()
Last week’s blog post taught us how to write videos to file using OpenCV and Python. This is a great skill to have, but it also raises the question:
How do I write video clips containing interesting events to file rather than the entire video?
In this case, the overall goal is to construct a video synopsis, distilling the most key, salient, and interesting parts of the video stream into a series of short video files.
What actually defines a “key or interesting event” is entirely up to you and your application. Potential examples of key events can include:
- Motion being detected in a restricted access zone.
- An intruder entering your house or apartment.
- A car running a stop sign on a busy street by your home.
In each of these cases, you’re not interested in the entire video capture — instead, you only want the video clip that contains the action!
To see how capturing key event video clips with OpenCV is done (and build your own video synopsis), just keep reading.
Saving key event video clips with OpenCV
The purpose of this blog post is to demonstrate how to write short video clips to file when a particular action takes place. We’ll be using our knowledge gained from last week’s blog post on writing video to file with OpenCV to implement this functionality.
As I mentioned at the top of this post, defining “key” and “interesting” events in a video stream is entirely dependent on your application and the overalls goals of what you’re trying to build.
You might be interesting in detecting motion in a room. Monitoring your house. Or creating a system to observe traffic and store clips of motor vehicle drivers breaking the law.
As a simple example of both:
- Defining a key event.
- Writing the video clip to file containing the event.
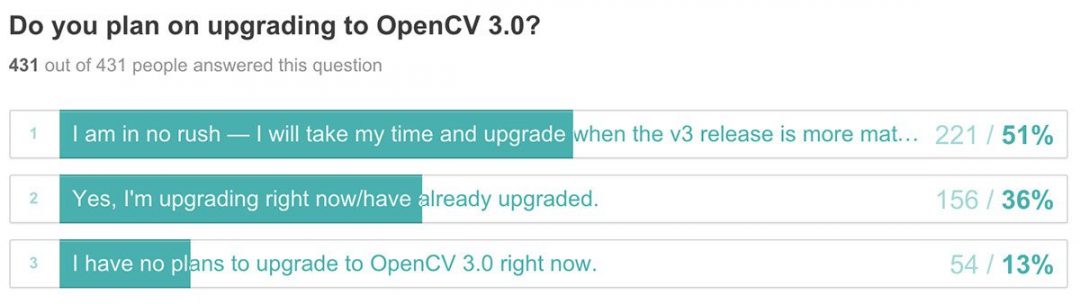
We’ll be processing a video streaming and looking for occurrences of this green ball:
![Figure 1: An example of the green ball we are going to detect in video streams.]()
Figure 1: An example of the green ball we are going to detect in video streams.
If this green ball appears in our video stream, we’ll open up a new file video (based on the timestamp of occurrence), write the clip to file, and then stop the writing process once the ball disappears from our view.
Furthermore, our implementation will have a number of desirable properties, including:
- Writing frames to our video file a few seconds before the action takes place.
- Writing frames to file a few seconds after the action finishes — in both cases, our goal is to not only capture the entire event, but also the context of the event as well.
- Utilizing threads to ensure our main program is not slowed down when performing I/O on both the input stream and the output video clip file.
- Leveraging built-in Python data structures such as
deque
and Queue
so we need not rely on external libraries (other than OpenCV and imutils, of course).
Project structure
Before we get started implementing our key event video writer, let’s look at the project structure:
|--- output
|--- pyimagesearch
| |--- __init__.py
| |--- keyclipwriter.py
|--- save_key_events.py
Inside the
pyimagesearch
module, we’ll define a class named
KeyClipWriter
inside the
keyclipwriter.py
file. This class will handle accepting frames from an input video stream ad writing them to file in a safe, efficient, and threaded manner.
The driver script,
save_key_events.py
, will define the criteria of what an “interesting event” is (i.e., the green ball entering the view of the camera), followed by passing these frames on to the
KeyClipWriter
which will then create our video synopsis.
A quick note on Python + OpenCV versions
This blog post assumes you are using Python 3+ and OpenCV 3. As I mentioned in last week’s post, I wasn’t able to get the
cv2.VideoWriter
function to work on my OpenCV 2.4 installation, so after a few hours of hacking around with no luck, I ended up abandoning OpenCV 2.4 for this project and sticking with OpenCV 3.
The code in this lesson is technically compatible with Python 2.7 (again, provided you are using Python 2.7 with OpenCV 3 bindings), but you’ll need to change a few
import
statements (I’ll point these out along the way).
Writing key/interesting video clips to file with OpenCV
Let’s go ahead and get started reviewing our
KeyClipWriter
class:
# import the necessary packages
from collections import deque
from threading import Thread
from queue import Queue
import time
import cv2
class KeyClipWriter:
def __init__(self, bufSize=64, timeout=1.0):
# store the maximum buffer size of frames to be kept
# in memory along with the sleep timeout during threading
self.bufSize = bufSize
self.timeout = timeout
# initialize the buffer of frames, queue of frames that
# need to be written to file, video writer, writer thread,
# and boolean indicating whether recording has started or not
self.frames = deque(maxlen=bufSize)
self.Q = None
self.writer = None
self.thread = None
self.recording = False
We start off by importing our required Python packages on Lines 2-6. This tutorial assumes you are using Python 3, so if you’re using Python 2.7, you’ll need to change Line 4 from
from queue import Queue
to simply
import Queue
.
Line 9 defines the constructor to our
KeyClipWriter
, which accepts two optional parameters:
bufSize
: The maximum number of frames to be keep cached in an in-memory buffer.timeout
: An integer representing the number of seconds to sleep for when (1) writing video clips to file and (2) there are no frames ready to be written.
We then initialize four important variables on Lines 18-22:
frames
: A buffer used to a store a maximum of bufSize
frames that have been most recently read from the video stream.Q
: A “first in, first out” (FIFO) Python Queue data structure used to hold frames that are awaiting to be written to video file.writer
: An instantiation of the cv2.VideoWriter
class used to actually write frames to the output video file.thread
: A Python Thread
instance that we’ll use when writing videos to file (to avoid costly I/O latency delays).recording
: Boolean value indicating whether or not we are in “recording mode”.
Next up, let’s review the
update
method:
# import the necessary packages
from collections import deque
from threading import Thread
from queue import Queue
import time
import cv2
class KeyClipWriter:
def __init__(self, bufSize=64, timeout=1.0):
# store the maximum buffer size of frames to be kept
# in memory along with the sleep timeout during threading
self.bufSize = bufSize
self.timeout = timeout
# initialize the buffer of frames, queue of frames that
# need to be written to file, video writer, writer thread,
# and boolean indicating whether recording has started or not
self.frames = deque(maxlen=bufSize)
self.Q = None
self.writer = None
self.thread = None
self.recording = False
def update(self, frame):
# update the frames buffer
self.frames.appendleft(frame)
# if we are recording, update the queue as well
if self.recording:
self.Q.put(frame)
The
update
function requires a single parameter, the
frame
read from our video stream. We take this
frame
and store it in our
frames
buffer (
Line 26). And if we are already in recording mode, we’ll store the
frame
in the
Queue
as well so it can be flushed to video file (
Lines 29 and 30).
In order to kick-off an actual video clip recording, we need a
start
method:
# import the necessary packages
from collections import deque
from threading import Thread
from queue import Queue
import time
import cv2
class KeyClipWriter:
def __init__(self, bufSize=64, timeout=1.0):
# store the maximum buffer size of frames to be kept
# in memory along with the sleep timeout during threading
self.bufSize = bufSize
self.timeout = timeout
# initialize the buffer of frames, queue of frames that
# need to be written to file, video writer, writer thread,
# and boolean indicating whether recording has started or not
self.frames = deque(maxlen=bufSize)
self.Q = None
self.writer = None
self.thread = None
self.recording = False
def update(self, frame):
# update the frames buffer
self.frames.appendleft(frame)
# if we are recording, update the queue as well
if self.recording:
self.Q.put(frame)
def start(self, outputPath, fourcc, fps):
# indicate that we are recording, start the video writer,
# and initialize the queue of frames that need to be written
# to the video file
self.recording = True
self.writer = cv2.VideoWriter(outputPath, fourcc, fps,
(self.frames[0].shape[1], self.frames[0].shape[0]), True)
self.Q = Queue()
# loop over the frames in the deque structure and add them
# to the queue
for i in range(len(self.frames), 0, -1):
self.Q.put(self.frames[i - 1])
# start a thread write frames to the video file
self.thread = Thread(target=self.write, args=())
self.thread.daemon = True
self.thread.start()
First, we update our
recording
boolean to indicate that we are in “recording mode”. Then, we initialize the
cv2.VideoWriter
using the supplied
outputPath
,
fourcc
, and
fps
provided to the
start
method, along with the frame spatial dimensions (i.e., width and height). For a complete review of the
cv2.VideoWriter
parameters,
please refer to this blog post.
Line 39 initializes our
Queue
used to store the frames ready to be written to file. We then loop over all frames in our
frames
buffer and add them to the queue.
Finally, we spawn a separate thread to handle writing frames to video — this way we don’t slow down our main video processing pipeline by waiting for I/O operations to complete.
As noted above, the
start
method creates a new thread, calling the
write
method used to write frames inside the
Q
to file. Let’s define this
write
method:
# import the necessary packages
from collections import deque
from threading import Thread
from queue import Queue
import time
import cv2
class KeyClipWriter:
def __init__(self, bufSize=64, timeout=1.0):
# store the maximum buffer size of frames to be kept
# in memory along with the sleep timeout during threading
self.bufSize = bufSize
self.timeout = timeout
# initialize the buffer of frames, queue of frames that
# need to be written to file, video writer, writer thread,
# and boolean indicating whether recording has started or not
self.frames = deque(maxlen=bufSize)
self.Q = None
self.writer = None
self.thread = None
self.recording = False
def update(self, frame):
# update the frames buffer
self.frames.appendleft(frame)
# if we are recording, update the queue as well
if self.recording:
self.Q.put(frame)
def start(self, outputPath, fourcc, fps):
# indicate that we are recording, start the video writer,
# and initialize the queue of frames that need to be written
# to the video file
self.recording = True
self.writer = cv2.VideoWriter(outputPath, fourcc, fps,
(self.frames[0].shape[1], self.frames[0].shape[0]), True)
self.Q = Queue()
# loop over the frames in the deque structure and add them
# to the queue
for i in range(len(self.frames), 0, -1):
self.Q.put(self.frames[i - 1])
# start a thread write frames to the video file
self.thread = Thread(target=self.write, args=())
self.thread.daemon = True
self.thread.start()
def write(self):
# keep looping
while True:
# if we are done recording, exit the thread
if not self.recording:
return
# check to see if there are entries in the queue
if not self.Q.empty():
# grab the next frame in the queue and write it
# to the video file
frame = self.Q.get()
self.writer.write(frame)
# otherwise, the queue is empty, so sleep for a bit
# so we don't waste CPU cycles
else:
time.sleep(self.timeout)
Line 53 starts an infinite loop that will continue polling for new frames and writing them to file until our video recording has finished.
Lines 55 and 56 make a check to see if the recording should be stopped, and if so, we return from the thread.
Otherwise, if the
Q
is not empty, we grab the next frame and write it to the video file (
Lines 59-63).
If there are no frames in the
Q
, we sleep for a bit so we don’t needlessly waste CPU cycles spinning (
Lines 67 and 68). This is
especially important when using the
Queue
data structure which is
thread-safe, implying that we must acquire a lock/semaphore prior to updating the internal buffer. If we don’t call
time.sleep
when the buffer is empty, then the
write
and
update
methods will constantly be fighting for the lock. Instead, it’s best to let the writer sleep for a bit until there are a backlog of frames in the queue that need to be written to file.
We’ll also define a
flush
method which simply takes all frames left in the
Q
and dumps them to file:
# import the necessary packages
from collections import deque
from threading import Thread
from queue import Queue
import time
import cv2
class KeyClipWriter:
def __init__(self, bufSize=64, timeout=1.0):
# store the maximum buffer size of frames to be kept
# in memory along with the sleep timeout during threading
self.bufSize = bufSize
self.timeout = timeout
# initialize the buffer of frames, queue of frames that
# need to be written to file, video writer, writer thread,
# and boolean indicating whether recording has started or not
self.frames = deque(maxlen=bufSize)
self.Q = None
self.writer = None
self.thread = None
self.recording = False
def update(self, frame):
# update the frames buffer
self.frames.appendleft(frame)
# if we are recording, update the queue as well
if self.recording:
self.Q.put(frame)
def start(self, outputPath, fourcc, fps):
# indicate that we are recording, start the video writer,
# and initialize the queue of frames that need to be written
# to the video file
self.recording = True
self.writer = cv2.VideoWriter(outputPath, fourcc, fps,
(self.frames[0].shape[1], self.frames[0].shape[0]), True)
self.Q = Queue()
# loop over the frames in the deque structure and add them
# to the queue
for i in range(len(self.frames), 0, -1):
self.Q.put(self.frames[i - 1])
# start a thread write frames to the video file
self.thread = Thread(target=self.write, args=())
self.thread.daemon = True
self.thread.start()
def write(self):
# keep looping
while True:
# if we are done recording, exit the thread
if not self.recording:
return
# check to see if there are entries in the queue
if not self.Q.empty():
# grab the next frame in the queue and write it
# to the video file
frame = self.Q.get()
self.writer.write(frame)
# otherwise, the queue is empty, so sleep for a bit
# so we don't waste CPU cycles
else:
time.sleep(self.timeout)
def flush(self):
# empty the queue by flushing all remaining frames to file
while not self.Q.empty():
frame = self.Q.get()
self.writer.write(frame)
A method like this is used when a video recording has finished and we need to immediately flush all frames to file.
Finally, we define the
finish
method below:
# import the necessary packages
from collections import deque
from threading import Thread
from queue import Queue
import time
import cv2
class KeyClipWriter:
def __init__(self, bufSize=64, timeout=1.0):
# store the maximum buffer size of frames to be kept
# in memory along with the sleep timeout during threading
self.bufSize = bufSize
self.timeout = timeout
# initialize the buffer of frames, queue of frames that
# need to be written to file, video writer, writer thread,
# and boolean indicating whether recording has started or not
self.frames = deque(maxlen=bufSize)
self.Q = None
self.writer = None
self.thread = None
self.recording = False
def update(self, frame):
# update the frames buffer
self.frames.appendleft(frame)
# if we are recording, update the queue as well
if self.recording:
self.Q.put(frame)
def start(self, outputPath, fourcc, fps):
# indicate that we are recording, start the video writer,
# and initialize the queue of frames that need to be written
# to the video file
self.recording = True
self.writer = cv2.VideoWriter(outputPath, fourcc, fps,
(self.frames[0].shape[1], self.frames[0].shape[0]), True)
self.Q = Queue()
# loop over the frames in the deque structure and add them
# to the queue
for i in range(len(self.frames), 0, -1):
self.Q.put(self.frames[i - 1])
# start a thread write frames to the video file
self.thread = Thread(target=self.write, args=())
self.thread.daemon = True
self.thread.start()
def write(self):
# keep looping
while True:
# if we are done recording, exit the thread
if not self.recording:
return
# check to see if there are entries in the queue
if not self.Q.empty():
# grab the next frame in the queue and write it
# to the video file
frame = self.Q.get()
self.writer.write(frame)
# otherwise, the queue is empty, so sleep for a bit
# so we don't waste CPU cycles
else:
time.sleep(self.timeout)
def flush(self):
# empty the queue by flushing all remaining frames to file
while not self.Q.empty():
frame = self.Q.get()
self.writer.write(frame)
def finish(self):
# indicate that we are done recording, join the thread,
# flush all remaining frames in the queue to file, and
# release the writer pointer
self.recording = False
self.thread.join()
self.flush()
self.writer.release()
This method indicates that the recording has been completed, joins the writer thread with the main script, flushes the remaining frames in the
Q
to file, and finally releases the
cv2.VideoWriter
pointer.
Now that we have defined the
KeyClipWriter
class, we can move on to the driver script used to implement the “key/interesting event” detection.
Saving key events with OpenCV
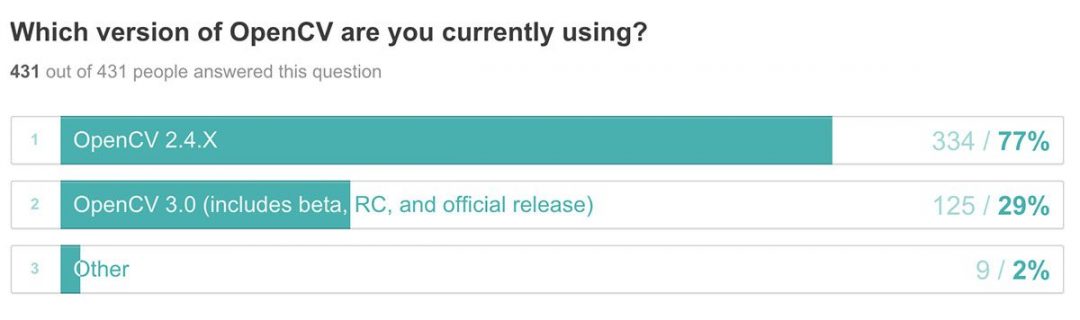
In order to keep this blog post simple and hands-on, we’ll define our “key event” to be when this green ball enters our video stream:
![Figure 2: An example of a key/interesting event in a video stream.]()
Figure 2: An example of a key/interesting event in a video stream.
Once we see this green ball, we will call
KeyClipWriter
to write all frames that contain the green ball to file. Essentially, this will give us a set of short video clips that neatly summarizes the events of the
entire video stream — in short,
a video synopsis.
Of course, you can use this code as a boilerplate/starting point to defining your own actions — we’ll simply use the “green ball” event since we have covered it multiple times before on the PyImageSearch blog, including tracking object movement and ball tracking.
Before you proceed with the rest of this tutorial, make sure you have the imutils package installed on your system:
$ pip install imutils
This will ensure that you can use the
VideoStream
class which creates a
unified access to both builtin/USB webcams and the Raspberry Pi camera module.
Let’s go ahead and get started. Open up the
save_key_events.py
file and insert the following code:
# import the necessary packages
from pyimagesearch.keyclipwriter import KeyClipWriter
from imutils.video import VideoStream
import argparse
import datetime
import imutils
import time
import cv2
# construct the argument parse and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-o", "--output", required=True,
help="path to output directory")
ap.add_argument("-p", "--picamera", type=int, default=-1,
help="whether or not the Raspberry Pi camera should be used")
ap.add_argument("-f", "--fps", type=int, default=20,
help="FPS of output video")
ap.add_argument("-c", "--codec", type=str, default="MJPG",
help="codec of output video")
ap.add_argument("-b", "--buffer-size", type=int, default=32,
help="buffer size of video clip writer")
args = vars(ap.parse_args())Lines 2-8 import our necessary Python packages while Lines 11-22 parse our command line arguments. The set of command line arguments are detailed below:
--output
: This is the path to the output directory where we will store the output video clips.--picamera
: If you want to use your Raspberry Pi camera (rather than a builtin/USB webcam), then supply a value of --picamera 1
. You can read more about accessing both builtin/USB webcams and the Raspberry Pi camera module (without changing a single line of code) in this post.--fps
: This switch controls the desired FPS of your output video. This value should be similar to the number of frames per second your image processing pipeline can process.--codec
: The FourCC codec of the output video clips. Please see the previous post for more information.--buffer-size
: The size of the in-memory buffer used to store the most recently polled frames from the camera sensor. A larger --buffer-size
will allow for more context before and after the “key event” to be included in the output video clip, while a smaller --buffer-size
will store less frames before and after the “key event”.
Let’s perform some initialization:
# import the necessary packages
from pyimagesearch.keyclipwriter import KeyClipWriter
from imutils.video import VideoStream
import argparse
import datetime
import imutils
import time
import cv2
# construct the argument parse and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-o", "--output", required=True,
help="path to output directory")
ap.add_argument("-p", "--picamera", type=int, default=-1,
help="whether or not the Raspberry Pi camera should be used")
ap.add_argument("-f", "--fps", type=int, default=20,
help="FPS of output video")
ap.add_argument("-c", "--codec", type=str, default="MJPG",
help="codec of output video")
ap.add_argument("-b", "--buffer-size", type=int, default=32,
help="buffer size of video clip writer")
args = vars(ap.parse_args())
# initialize the video stream and allow the camera sensor to
# warmup
print("[INFO] warming up camera...")
vs = VideoStream(usePiCamera=args["picamera"] > 0).start()
time.sleep(2.0)
# define the lower and upper boundaries of the "green" ball in
# the HSV color space
greenLower = (29, 86, 6)
greenUpper = (64, 255, 255)
# initialize key clip writer and the consecutive number of
# frames that have *not* contained any action
kcw = KeyClipWriter(bufSize=args["buffer_size"])
consecFrames = 0Lines 26-28 initialize our
VideoStream
and allow the camera sensor to warmup.
From there, Lines 32 and 33 define the lower and upper color threshold boundaries for the green ball in the HSV color space. For more information on how we defined these color threshold values, please see this post.
Line 37 instantiates our
KeyClipWriter
using our supplied
--buffer-size
, along with initializing an integer used to count the number of
consecutive frames that
have not contained any interesting events.
We are now ready to start processing frames from our video stream:
# import the necessary packages
from pyimagesearch.keyclipwriter import KeyClipWriter
from imutils.video import VideoStream
import argparse
import datetime
import imutils
import time
import cv2
# construct the argument parse and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-o", "--output", required=True,
help="path to output directory")
ap.add_argument("-p", "--picamera", type=int, default=-1,
help="whether or not the Raspberry Pi camera should be used")
ap.add_argument("-f", "--fps", type=int, default=20,
help="FPS of output video")
ap.add_argument("-c", "--codec", type=str, default="MJPG",
help="codec of output video")
ap.add_argument("-b", "--buffer-size", type=int, default=32,
help="buffer size of video clip writer")
args = vars(ap.parse_args())
# initialize the video stream and allow the camera sensor to
# warmup
print("[INFO] warming up camera...")
vs = VideoStream(usePiCamera=args["picamera"] > 0).start()
time.sleep(2.0)
# define the lower and upper boundaries of the "green" ball in
# the HSV color space
greenLower = (29, 86, 6)
greenUpper = (64, 255, 255)
# initialize key clip writer and the consecutive number of
# frames that have *not* contained any action
kcw = KeyClipWriter(bufSize=args["buffer_size"])
consecFrames = 0
# keep looping
while True:
# grab the current frame, resize it, and initialize a
# boolean used to indicate if the consecutive frames
# counter should be updated
frame = vs.read()
frame = imutils.resize(frame, width=600)
updateConsecFrames = True
# blur the frame and convert it to the HSV color space
blurred = cv2.GaussianBlur(frame, (11, 11), 0)
hsv = cv2.cvtColor(blurred, cv2.COLOR_BGR2HSV)
# construct a mask for the color "green", then perform
# a series of dilations and erosions to remove any small
# blobs left in the mask
mask = cv2.inRange(hsv, greenLower, greenUpper)
mask = cv2.erode(mask, None, iterations=2)
mask = cv2.dilate(mask, None, iterations=2)
# find contours in the mask
cnts = cv2.findContours(mask.copy(), cv2.RETR_EXTERNAL,
cv2.CHAIN_APPROX_SIMPLE)
cnts = cnts[0] if imutils.is_cv2() else cnts[1]On Line 41 we start to looping over frames from our video stream. Lines 45 and 46 read the next
frame
from the video stream and then resizes it to have a width of 600 pixels.
Further pre-processing is done on Lines 50 and 51 by blurring the image slightly and then converting the image from the RGB color space to the HSV color space (so we can apply our color thresholding).
The actual color thresholding is performed on Line 56 using the
cv2.inRange
function. This method finds all pixels
p that are
greenLower <= p <= greenUpper
. We then perform a series of erosions and dilations to remove any small blobs left in the mask.
Finally, Lines 61-63 find contours in the thresholded image.
If you are confused about any step of this processing pipeline, I would suggest going back to our previous posts on ball tracking and object movement to further familiarize yourself with the topic.
We are now ready to check and see if the green ball was found in our image:
# import the necessary packages
from pyimagesearch.keyclipwriter import KeyClipWriter
from imutils.video import VideoStream
import argparse
import datetime
import imutils
import time
import cv2
# construct the argument parse and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-o", "--output", required=True,
help="path to output directory")
ap.add_argument("-p", "--picamera", type=int, default=-1,
help="whether or not the Raspberry Pi camera should be used")
ap.add_argument("-f", "--fps", type=int, default=20,
help="FPS of output video")
ap.add_argument("-c", "--codec", type=str, default="MJPG",
help="codec of output video")
ap.add_argument("-b", "--buffer-size", type=int, default=32,
help="buffer size of video clip writer")
args = vars(ap.parse_args())
# initialize the video stream and allow the camera sensor to
# warmup
print("[INFO] warming up camera...")
vs = VideoStream(usePiCamera=args["picamera"] > 0).start()
time.sleep(2.0)
# define the lower and upper boundaries of the "green" ball in
# the HSV color space
greenLower = (29, 86, 6)
greenUpper = (64, 255, 255)
# initialize key clip writer and the consecutive number of
# frames that have *not* contained any action
kcw = KeyClipWriter(bufSize=args["buffer_size"])
consecFrames = 0
# keep looping
while True:
# grab the current frame, resize it, and initialize a
# boolean used to indicate if the consecutive frames
# counter should be updated
frame = vs.read()
frame = imutils.resize(frame, width=600)
updateConsecFrames = True
# blur the frame and convert it to the HSV color space
blurred = cv2.GaussianBlur(frame, (11, 11), 0)
hsv = cv2.cvtColor(blurred, cv2.COLOR_BGR2HSV)
# construct a mask for the color "green", then perform
# a series of dilations and erosions to remove any small
# blobs left in the mask
mask = cv2.inRange(hsv, greenLower, greenUpper)
mask = cv2.erode(mask, None, iterations=2)
mask = cv2.dilate(mask, None, iterations=2)
# find contours in the mask
cnts = cv2.findContours(mask.copy(), cv2.RETR_EXTERNAL,
cv2.CHAIN_APPROX_SIMPLE)
cnts = cnts[0] if imutils.is_cv2() else cnts[1]
# only proceed if at least one contour was found
if len(cnts) > 0:
# find the largest contour in the mask, then use it
# to compute the minimum enclosing circle
c = max(cnts, key=cv2.contourArea)
((x, y), radius) = cv2.minEnclosingCircle(c)
updateConsecFrames = radius <= 10
# only proceed if the redius meets a minimum size
if radius > 10:
# reset the number of consecutive frames with
# *no* action to zero and draw the circle
# surrounding the object
consecFrames = 0
cv2.circle(frame, (int(x), int(y)), int(radius),
(0, 0, 255), 2)
# if we are not already recording, start recording
if not kcw.recording:
timestamp = datetime.datetime.now()
p = "{}/{}.avi".format(args["output"],
timestamp.strftime("%Y%m%d-%H%M%S"))
kcw.start(p, cv2.VideoWriter_fourcc(*args["codec"]),
args["fps"])Line 66 makes a check to ensure that at least one contour was found, and if so, Line 69 and 70 find the largest contour in the mask (according to the area) and use this contour to compute the minimum enclosing circle.
If the radius of the circle meets a minimum suze of 10 pixels (Line 74), then we will assume that we have found the green ball. Lines 78-80 reset the number of
consecFrames
that do not contain any interesting events (since an interesting event is “currently happening”) and draw a circle highlighting our ball in the frame.
Finally, we make a check if to see if we are currently recording a video clip (Line 83). If not, we generate an output filename for the video clip based on the current timestamp and call the
start
method of the
KeyClipWriter
.
Otherwise, we’ll assume no key/interesting event has taken place:
# import the necessary packages
from pyimagesearch.keyclipwriter import KeyClipWriter
from imutils.video import VideoStream
import argparse
import datetime
import imutils
import time
import cv2
# construct the argument parse and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-o", "--output", required=True,
help="path to output directory")
ap.add_argument("-p", "--picamera", type=int, default=-1,
help="whether or not the Raspberry Pi camera should be used")
ap.add_argument("-f", "--fps", type=int, default=20,
help="FPS of output video")
ap.add_argument("-c", "--codec", type=str, default="MJPG",
help="codec of output video")
ap.add_argument("-b", "--buffer-size", type=int, default=32,
help="buffer size of video clip writer")
args = vars(ap.parse_args())
# initialize the video stream and allow the camera sensor to
# warmup
print("[INFO] warming up camera...")
vs = VideoStream(usePiCamera=args["picamera"] > 0).start()
time.sleep(2.0)
# define the lower and upper boundaries of the "green" ball in
# the HSV color space
greenLower = (29, 86, 6)
greenUpper = (64, 255, 255)
# initialize key clip writer and the consecutive number of
# frames that have *not* contained any action
kcw = KeyClipWriter(bufSize=args["buffer_size"])
consecFrames = 0
# keep looping
while True:
# grab the current frame, resize it, and initialize a
# boolean used to indicate if the consecutive frames
# counter should be updated
frame = vs.read()
frame = imutils.resize(frame, width=600)
updateConsecFrames = True
# blur the frame and convert it to the HSV color space
blurred = cv2.GaussianBlur(frame, (11, 11), 0)
hsv = cv2.cvtColor(blurred, cv2.COLOR_BGR2HSV)
# construct a mask for the color "green", then perform
# a series of dilations and erosions to remove any small
# blobs left in the mask
mask = cv2.inRange(hsv, greenLower, greenUpper)
mask = cv2.erode(mask, None, iterations=2)
mask = cv2.dilate(mask, None, iterations=2)
# find contours in the mask
cnts = cv2.findContours(mask.copy(), cv2.RETR_EXTERNAL,
cv2.CHAIN_APPROX_SIMPLE)
cnts = cnts[0] if imutils.is_cv2() else cnts[1]
# only proceed if at least one contour was found
if len(cnts) > 0:
# find the largest contour in the mask, then use it
# to compute the minimum enclosing circle
c = max(cnts, key=cv2.contourArea)
((x, y), radius) = cv2.minEnclosingCircle(c)
updateConsecFrames = radius <= 10
# only proceed if the redius meets a minimum size
if radius > 10:
# reset the number of consecutive frames with
# *no* action to zero and draw the circle
# surrounding the object
consecFrames = 0
cv2.circle(frame, (int(x), int(y)), int(radius),
(0, 0, 255), 2)
# if we are not already recording, start recording
if not kcw.recording:
timestamp = datetime.datetime.now()
p = "{}/{}.avi".format(args["output"],
timestamp.strftime("%Y%m%d-%H%M%S"))
kcw.start(p, cv2.VideoWriter_fourcc(*args["codec"]),
args["fps"])
# otherwise, no action has taken place in this frame, so
# increment the number of consecutive frames that contain
# no action
if updateConsecFrames:
consecFrames += 1
# update the key frame clip buffer
kcw.update(frame)
# if we are recording and reached a threshold on consecutive
# number of frames with no action, stop recording the clip
if kcw.recording and consecFrames == args["buffer_size"]:
kcw.finish()
# show the frame
cv2.imshow("Frame", frame)
key = cv2.waitKey(1) & 0xFF
# if the `q` key was pressed, break from the loop
if key == ord("q"):
breakIf no interesting event has happened, we update
consecFrames
and pass the
frame
over to our buffer.
Line 101 makes an important check — if we are recording and have reached a sufficient number of consecutive frames with no key event, then we should stop the recording.
Finally, Lines 105-110 display the output
frame
to our screen and wait for a keypress.
Our final block of code ensures the video has been successfully closed and then performs a bit of cleanup:
# import the necessary packages
from pyimagesearch.keyclipwriter import KeyClipWriter
from imutils.video import VideoStream
import argparse
import datetime
import imutils
import time
import cv2
# construct the argument parse and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-o", "--output", required=True,
help="path to output directory")
ap.add_argument("-p", "--picamera", type=int, default=-1,
help="whether or not the Raspberry Pi camera should be used")
ap.add_argument("-f", "--fps", type=int, default=20,
help="FPS of output video")
ap.add_argument("-c", "--codec", type=str, default="MJPG",
help="codec of output video")
ap.add_argument("-b", "--buffer-size", type=int, default=32,
help="buffer size of video clip writer")
args = vars(ap.parse_args())
# initialize the video stream and allow the camera sensor to
# warmup
print("[INFO] warming up camera...")
vs = VideoStream(usePiCamera=args["picamera"] > 0).start()
time.sleep(2.0)
# define the lower and upper boundaries of the "green" ball in
# the HSV color space
greenLower = (29, 86, 6)
greenUpper = (64, 255, 255)
# initialize key clip writer and the consecutive number of
# frames that have *not* contained any action
kcw = KeyClipWriter(bufSize=args["buffer_size"])
consecFrames = 0
# keep looping
while True:
# grab the current frame, resize it, and initialize a
# boolean used to indicate if the consecutive frames
# counter should be updated
frame = vs.read()
frame = imutils.resize(frame, width=600)
updateConsecFrames = True
# blur the frame and convert it to the HSV color space
blurred = cv2.GaussianBlur(frame, (11, 11), 0)
hsv = cv2.cvtColor(blurred, cv2.COLOR_BGR2HSV)
# construct a mask for the color "green", then perform
# a series of dilations and erosions to remove any small
# blobs left in the mask
mask = cv2.inRange(hsv, greenLower, greenUpper)
mask = cv2.erode(mask, None, iterations=2)
mask = cv2.dilate(mask, None, iterations=2)
# find contours in the mask
cnts = cv2.findContours(mask.copy(), cv2.RETR_EXTERNAL,
cv2.CHAIN_APPROX_SIMPLE)
cnts = cnts[0] if imutils.is_cv2() else cnts[1]
# only proceed if at least one contour was found
if len(cnts) > 0:
# find the largest contour in the mask, then use it
# to compute the minimum enclosing circle
c = max(cnts, key=cv2.contourArea)
((x, y), radius) = cv2.minEnclosingCircle(c)
updateConsecFrames = radius <= 10
# only proceed if the redius meets a minimum size
if radius > 10:
# reset the number of consecutive frames with
# *no* action to zero and draw the circle
# surrounding the object
consecFrames = 0
cv2.circle(frame, (int(x), int(y)), int(radius),
(0, 0, 255), 2)
# if we are not already recording, start recording
if not kcw.recording:
timestamp = datetime.datetime.now()
p = "{}/{}.avi".format(args["output"],
timestamp.strftime("%Y%m%d-%H%M%S"))
kcw.start(p, cv2.VideoWriter_fourcc(*args["codec"]),
args["fps"])
# otherwise, no action has taken place in this frame, so
# increment the number of consecutive frames that contain
# no action
if updateConsecFrames:
consecFrames += 1
# update the key frame clip buffer
kcw.update(frame)
# if we are recording and reached a threshold on consecutive
# number of frames with no action, stop recording the clip
if kcw.recording and consecFrames == args["buffer_size"]:
kcw.finish()
# show the frame
cv2.imshow("Frame", frame)
key = cv2.waitKey(1) & 0xFF
# if the `q` key was pressed, break from the loop
if key == ord("q"):
break
# if we are in the middle of recording a clip, wrap it up
if kcw.recording:
kcw.finish()
# do a bit of cleanup
cv2.destroyAllWindows()
vs.stop()
Video synopsis results
To generate video clips for key events (i.e., the green ball appearing on our video stream), just execute the following command:
$ python save_key_events.py --output output
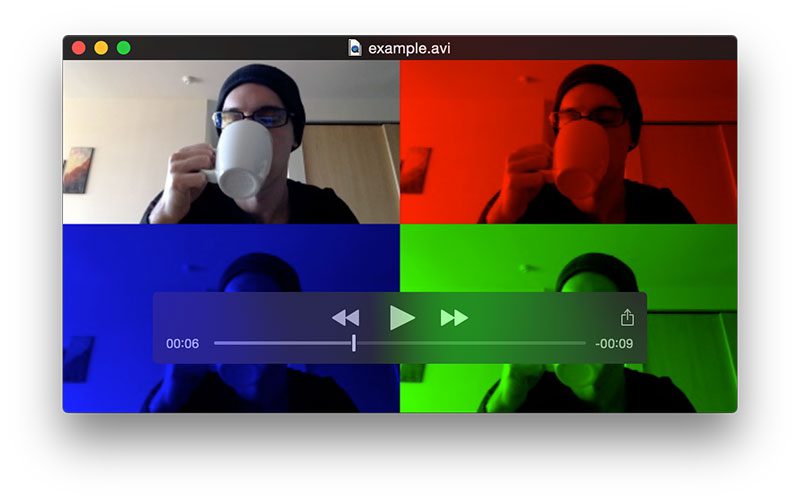
I’ve included the full 1m 46s video (without extracting salient clips) below:
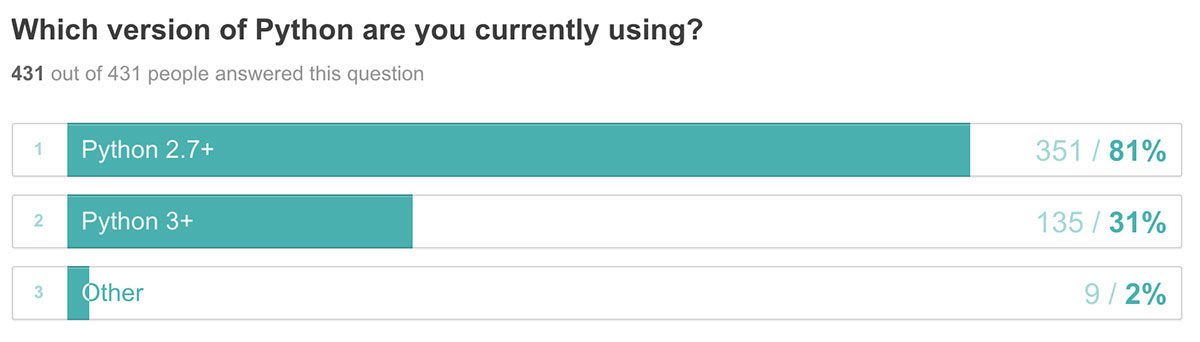
After running the
save_key_events.py
script, I now have
4 output videos, one for each the time green ball was present in my video stream:
![Figure 3: Creating a separate video clip for each interesting and key event.]()
Figure 3: Creating a separate video clip for each interesting and key event.
The key event video clips are displayed below to demonstrate that our script is working properly, accurately extracting our “interesting events”, and essentially building a series of video clips functioning as a video synopsis:
Video clip #1:
Video clip #2:
Video clip #3:
Video clip #4:
Summary
In this blog post, we learned how to save key event video clips to file using OpenCV and Python.
Exactly what defines a “key or interesting event” is entirely dependent on your application and the goals of your overall project. Examples of key events can include:
- Monitoring your front door for motion detection (i.e., someone entering your house).
- Recognizing the face of an intruder as they enter your house.
- Reporting unsafe driving outside your home to the authorities.
Again, exactly what constitutes a “key event” is near endless. However, regardless of how you define an interesting event, you can still use the Python code detailed in this post to help save these interesting events to file as a shortened video clip.
Using this methodology, you can condense hours of video stream footage into seconds of interesting events, effectively yielding a video synopsis — all generated using Python, computer vision, and image processing techniques.
Anyway, I hope you enjoyed this blog post!
If you did, please consider sharing it on your favorite social media outlet such as Facebook, Twitter, LinkedIn, etc. I put a lot of effort into the past two blog posts in this series and I would really appreciate it if you could help spread the word.
And before you, be sure to signup for the PyImageSearch Newsletter using the form below to receive email updates when new posts go live!
Downloads:
The post Saving key event video clips with OpenCV appeared first on PyImageSearch.


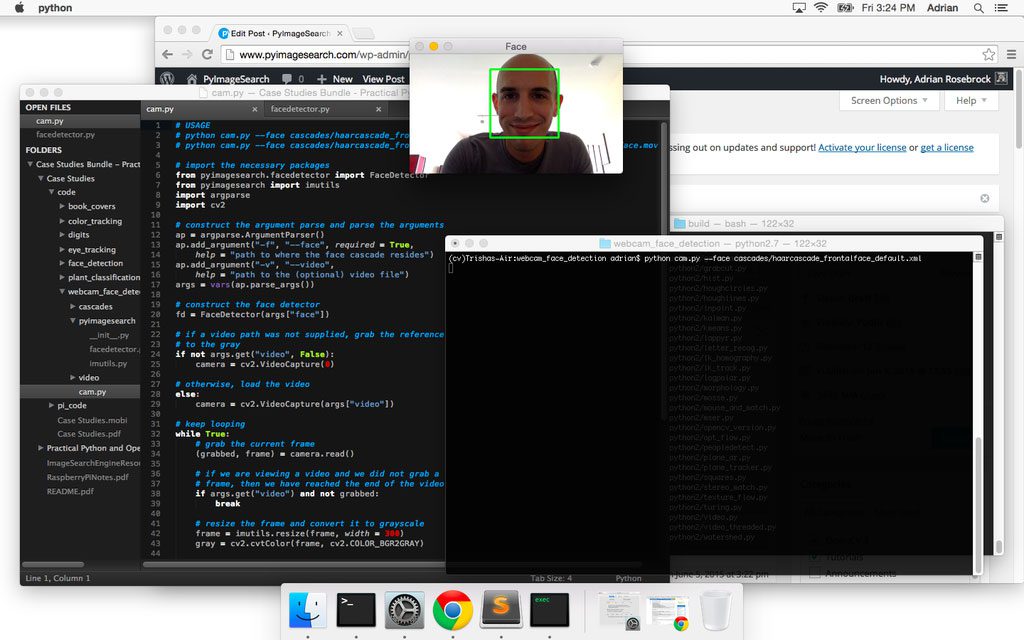

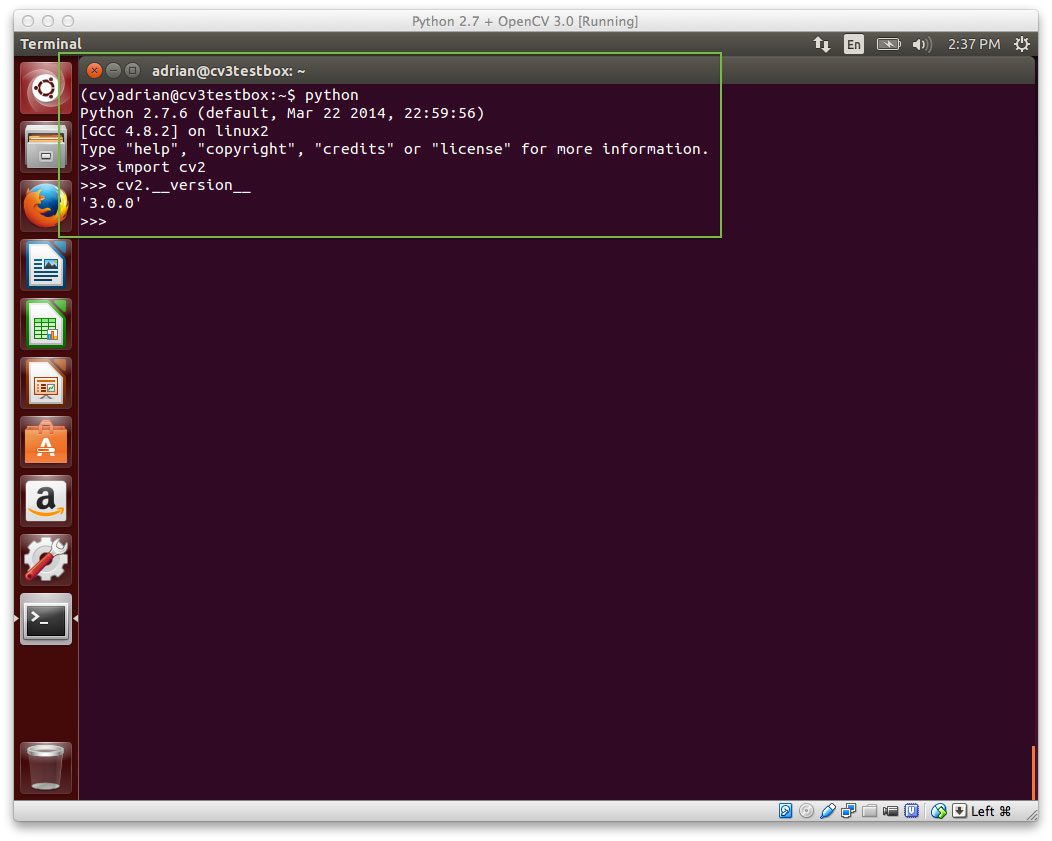

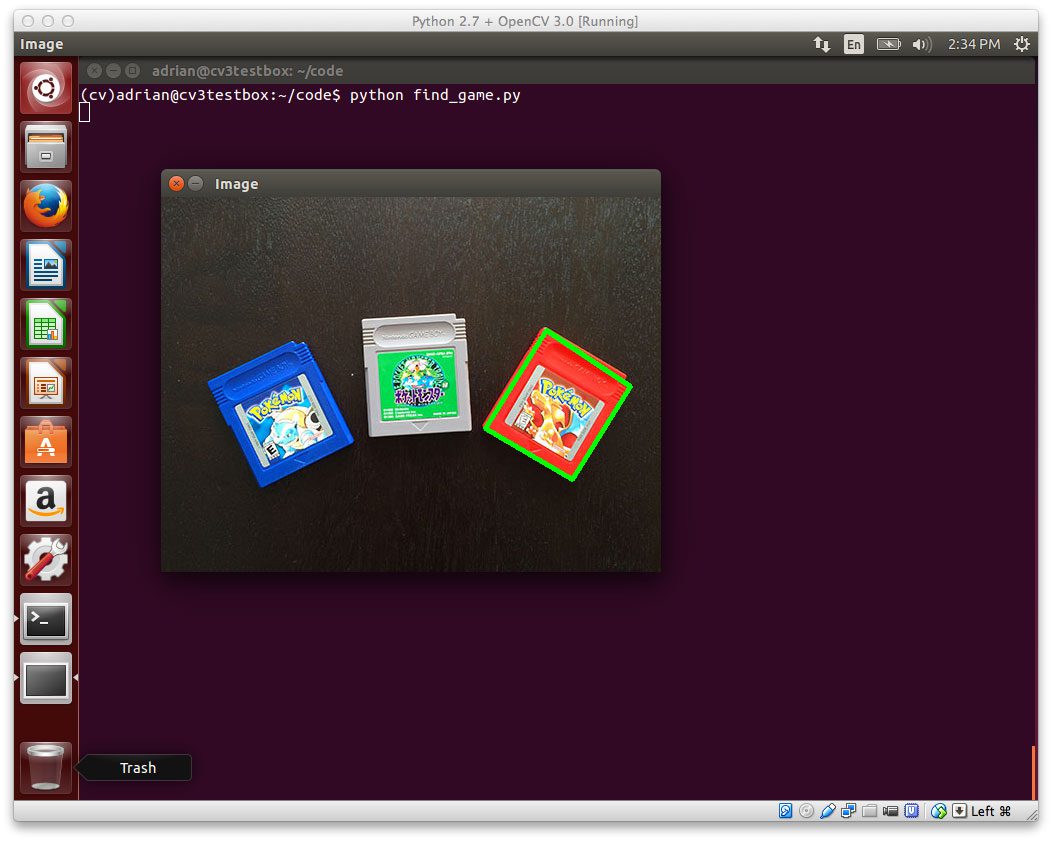
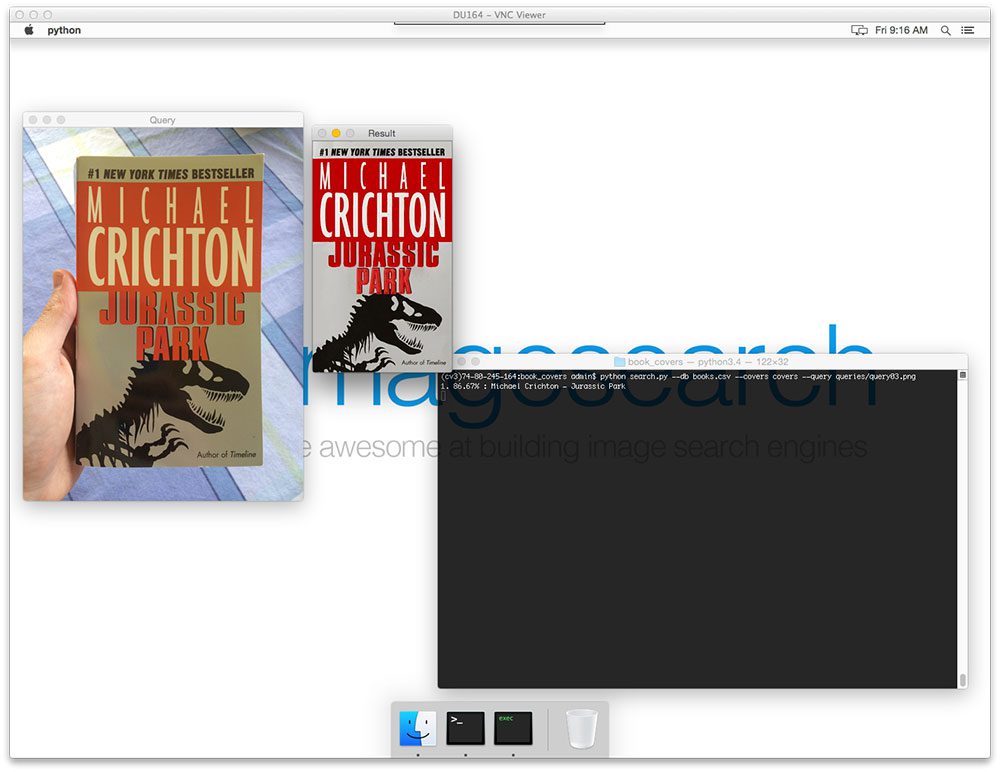



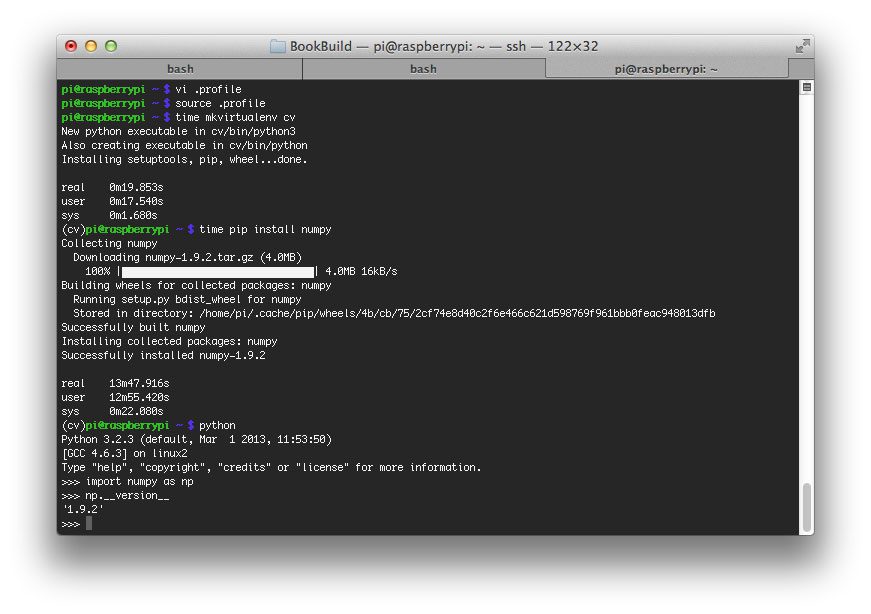
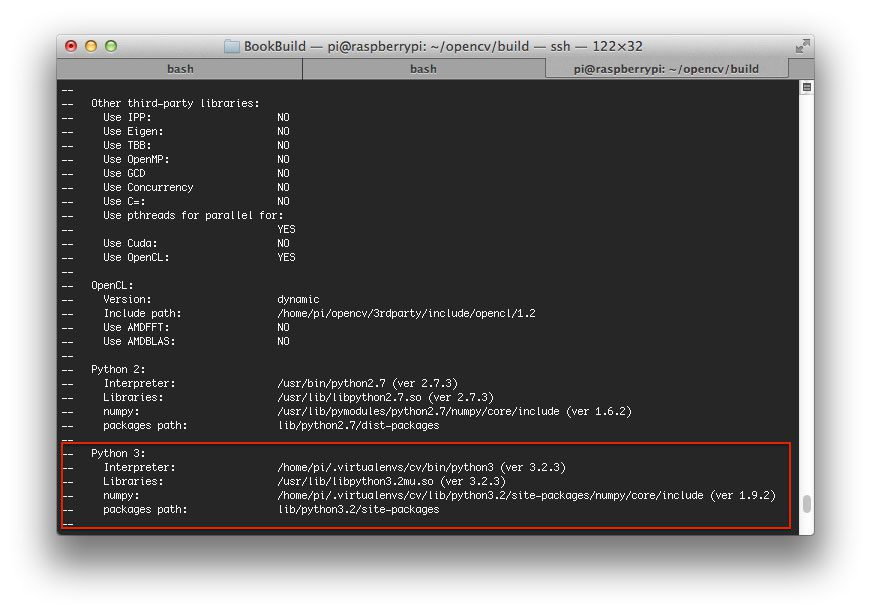
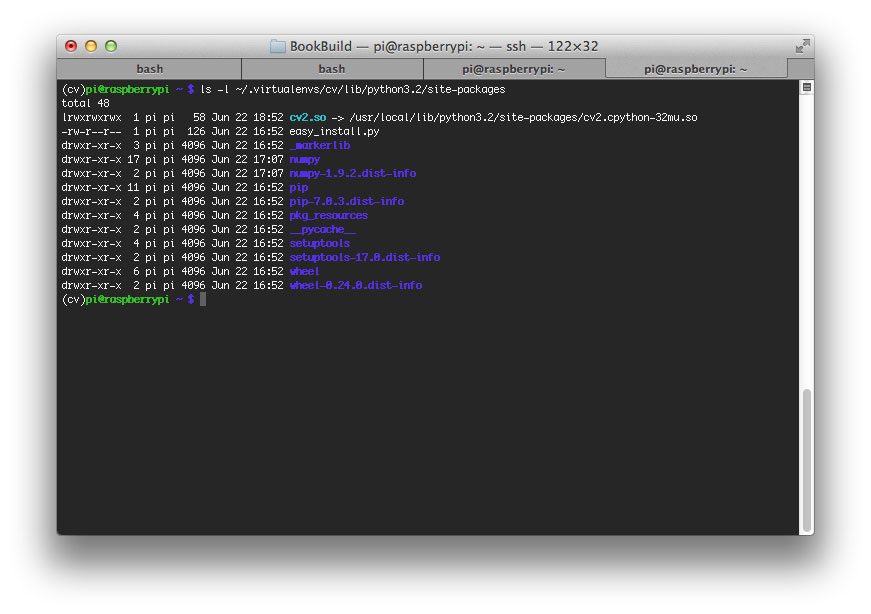
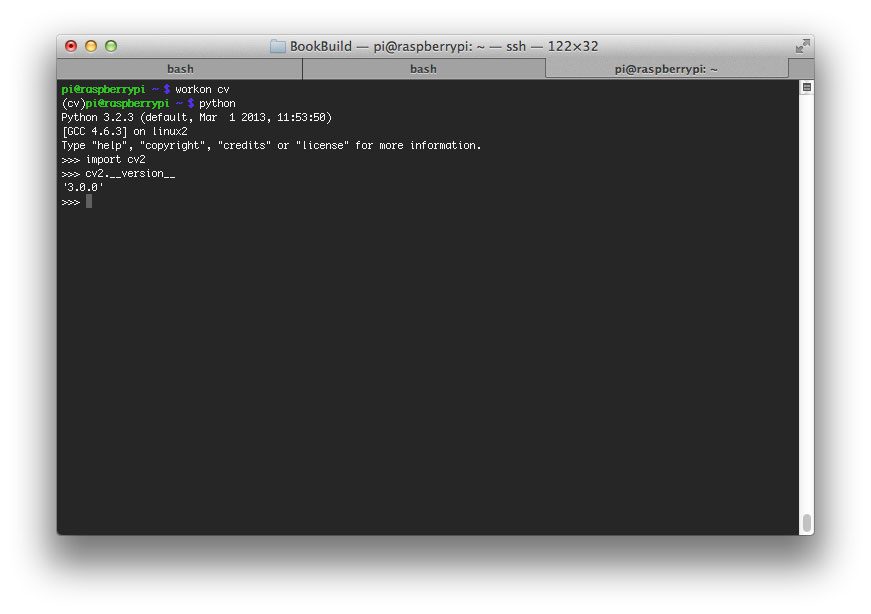



























 A few weeks ago, I wrote a blog post on
A few weeks ago, I wrote a blog post on 






